研究方向
最後更新:2024/12/12
最後更新:2024/12/12
- 基礎研究
- 參與成員:陳冠宇
- 研究題目
- 小型化Transformer的研究與開發
- 智慧法學
- 參與成員:劉兆崴、(鄭宇翔)、周騏軍、(黃柏熏)、113專題A組、113專題E組
- 研究題目:
- 車禍慰撫金預測
- ECHR歐洲人權法院判決預測
- 法律書類自動輔助完成系統
- 異常偵測
- 參與成員:林延昕、黃柏熏、113專題D組
- 研究題目:
- 基於視覺語言模型的監控影片異常事件偵測
- 車牌識別強化
- 竄改偵測
- 參與成員:朱俊豪、[鄭承斌]、[楊子誼]
- 研究題目:
- 基於深度學習的影片生成偵測
- 基於頻率域的影像竄改偵測
- 以對抗性樣本降低竄改偵測系統能力之研究
- 書法生成
- 參與成員:連鄭勳、[江岱樺]、[楊子誼]
- 研究題目:
- 以GAN方法將手寫字轉換為書法字風格字體之研究
- 以Diffusion方法將手寫字轉換為書法字風格字體之研究
- 建物勘查
- 參與成員:胡昭宇
- 研究題目:
- 牆壁裂縫的分類與偵測
- 影像審美
- 參與成員:[俞柏丞]、*(朱俊豪)、*(黃柏熏)、*(周騏軍) *因FITI競賽加入
- 研究題目:
- 智慧型拍照指引
- 基於視覺語言模型的影像自動評論指引系統
- 遊戲設計
- 參與成員:113專題B組、113專題C組
-
研究題目:
- 手勢辨識與Unity遊戲的整合研究
- 大型語言模型與問答遊戲的整合研究

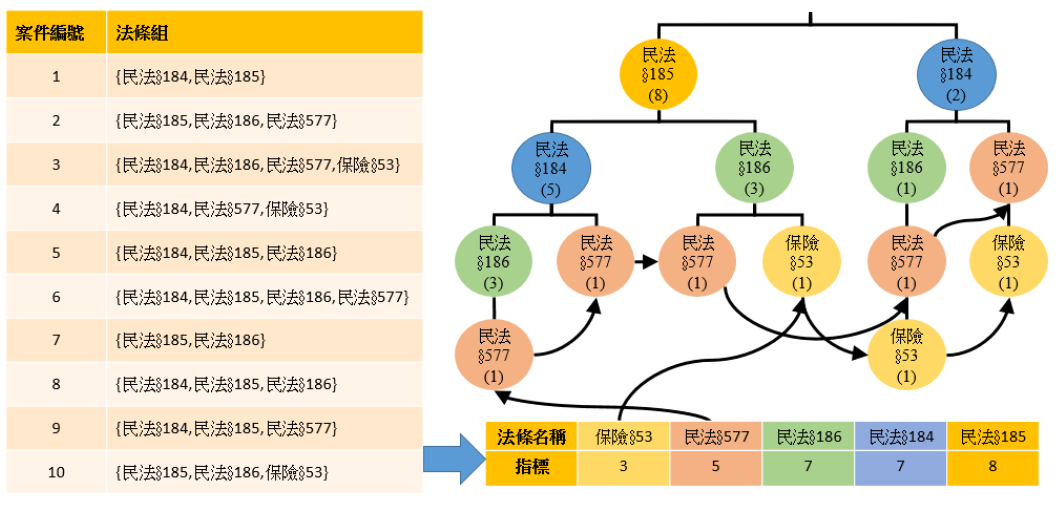
判決勝負預測
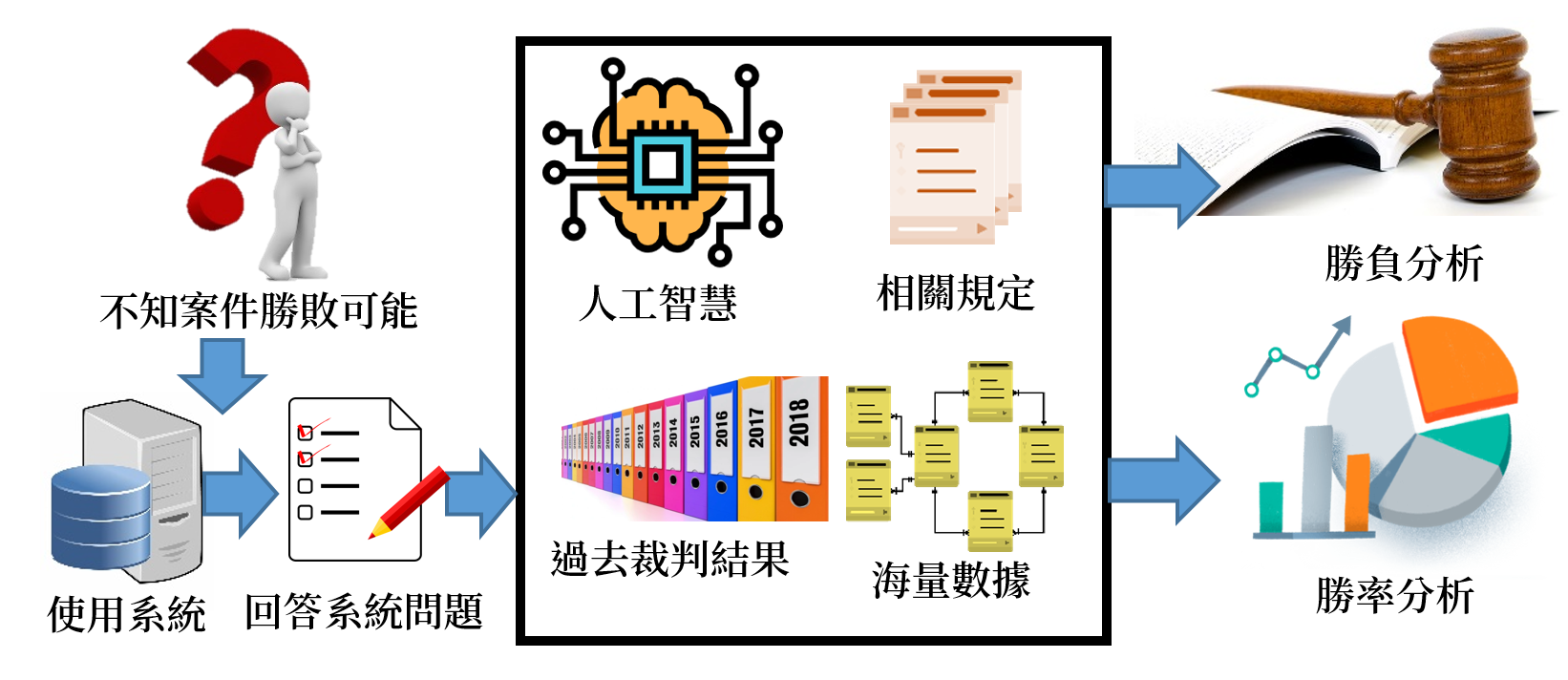 透過自然語言處理與資料探勘技術,從過去大量法律文件中,找出判斷依據,幫助法務人員節省辦案時間,並提升決策準確度。
透過自然語言處理與資料探勘技術,從過去大量法律文件中,找出判斷依據,幫助法務人員節省辦案時間,並提升決策準確度。
異常偵測技術
針對監視錄影器的畫面做自動分析,不須使用者定義,自動學習場景樣態,並主動發現可疑之移動物體。
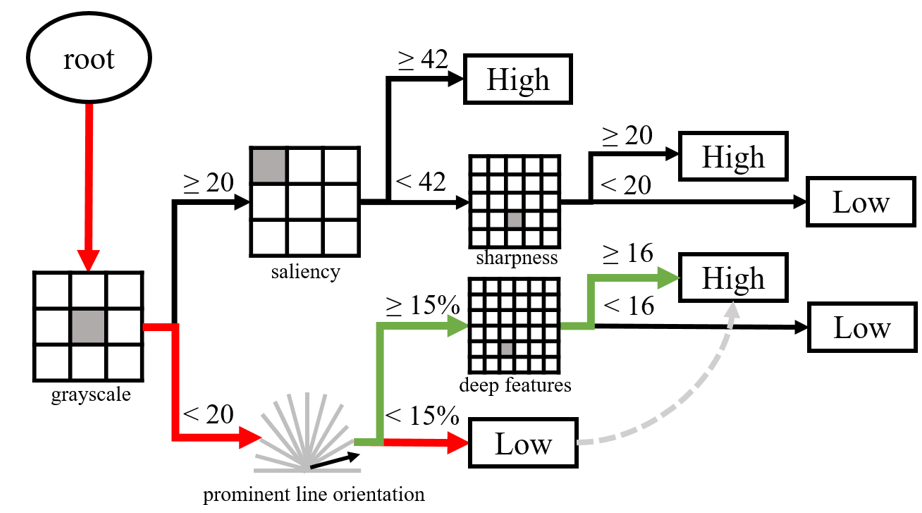
即時拍照指引

現今手機相機越來越先進,但缺乏拍照經驗的人不一定能拍出好照片。我們透過機器學習讓電腦即時教導使用者如何構圖,以及調整色調。